High Availability WordPress LAMP Stack – Part 2
This article is the second in a series (see part 1 here). Please see HA Network for the first part in setting up the network topology to be highly available.
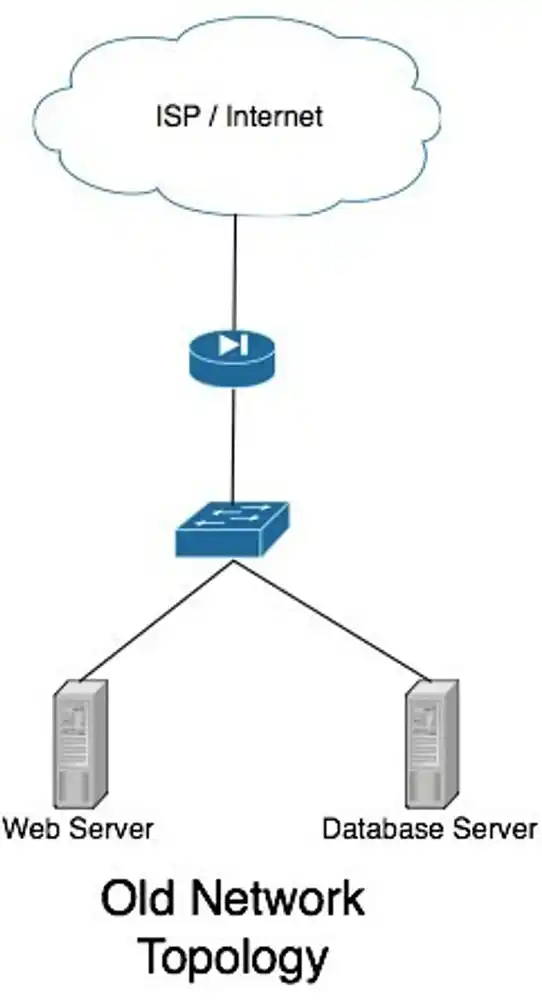
It’s all good having a redundant network design, but putting web servers and the like on our hypervisors doesn’t make them redundant. In the event where there’s a failure on one of our servers, all virtual machines on that server will die. Looking at our previous network design, we can see a failure on a web server or database server would cause service outage.
In this example, I’m going to talk about a few pretty cool pieces of software that you can use to make a highly available (HA) service stack for hosting Apache web sites from a MySQL data store. This post isn’t going to be about all the in’s and out’s of how to accomplish, but hopefully it will answer some questions you might have when setting out to accomplish this task as well as point you to the appropriate articles to help you achieve what you’re after.
Nginx load balancing proxy
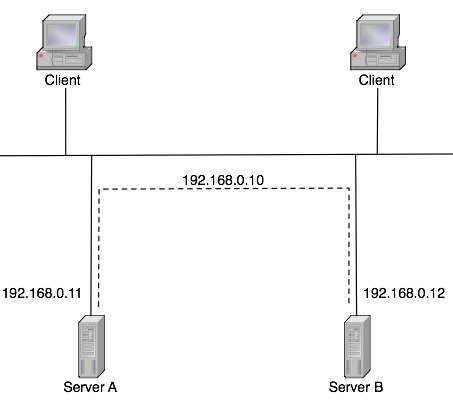
Lets look first at an example of a previous example. Lets take a simple network where we have a web server with a client. The A record for www.example.com points to our web server at 192.168.0.10 (of course we’d use NAT on the firewalls in my example to expose it to the internet).
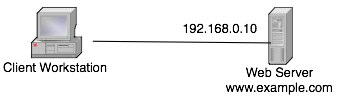
From my previous post, we can tell that the network topology to reach our web server on 192.168.0.10 is highly redundant, if the server itself, or the physical machine it’s hosted on in the case of virtual machines does die, we can no longer serve web pages.
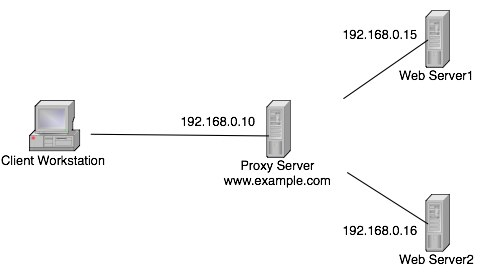
To solve this problem, we’re going to create multiple web servers. The A record for www.example.com is now no longer going to be pointing to the web server itself, but a proxy server (I recommend Nginx.) Now you can see that if either web server dies, our proxy server is able to start handing out requests through the other server. This method is also recommended because it mitigates load from a single server. If your web site got more popular, we can just start scaling out and adding more web servers into the mix to handle the load. Now, I know what you’re thinking, and yes, we have just moved the single point of failure from the web server to the proxy server, but please read on to find out how to protect that host from failure.
Heartbeat, keep your servers beating
In the previous example, we had a server that was a single point of failure. If the proxy server in this case died, then our web site would go down. To plan against the failure of this machine, you can set up a tool such as Heartbeat. An example works like the following, your proxy server above is running the Nginx daemon handling your client’s requests, but it does so using a virtual network adaptor where it’s IP address 192.168.0.10 sits. You put a second server in here in the mix with the same Nginx daemon and the same configuration, but it’s not running or serving anything, this is known as our slave server. The slave server is sending heartbeat messages to the master server. In the event that the master server stops responding to the slave’s heartbeat messages, it assumes the master is down and will create a virtual adaptor assuming the working IP address (192.168.0.10 in our example) and brings up the master services.
I use heartbeat extensively through my HA configurations. Not only for allowing services to be taken up by a slave in the event of a master failure, but also where I have clusters (for example, a MySQL cluster). When the slave assumes the master’s IP address, it’s handy to write a little script/service here to stop any replication and assume the master’s role.
ProTip: Managing configuration across your servers when you start creating multiple instances for redundancy can start to get out of hand very quickly. Sometimes you can change a configuration on one server and forget to do it on another. I suggest using a tool like Puppet to manage the configuration on your servers for you
ProTip: From experience, I’ve had situations in failover testing where the failure of a core switch will cause heartbeat to stop receiving heartbeats and fail the servers over, even though the physical and virtual machines themselves are fine. If you’re running the (non-rapid) Spanning Tree Protocol (STP) on your network, I suggest making the timeout for Heartbeat about 45 seconds. This should be enough time to allow for STP convergence before it assumes it’s partner is dead.
NFS File Store
In the example above, we’ve got multiple web servers. As I’ve said, this setup could be used to host a HA WordPress site. The problem is that when content that sits on the file system (such as an image or theme uploaded, wordpress upgrade, etc) takes place, it will no longer be in sync with the other web servers. For us, hosting the wordpress installation from an NFS mount point worked fine, which begins a thought on how to make this NFS server highly available.
Just like the previous example, we’re going to use Heartbeat to make sure we’ve got a master and slave, and that when the master fails, the slave will start hosting the NFS services. There’s only one more added piece of complexity here. If the master fails, the slave has none of the data that was stored on the master. To get around this, I’m using a tool called DRBD. DRBD allows a block device to be created and synced across multiple hosts. When you write to this device, data is replicated on the slave too. That way when the master dies and the slave takes it’s roll, it will have all the data that existed previously on the master. A good tutorial to set this up can be found HERE
ProTip: Once again from experience, when everything is not working as expected, having the slave be promoted is a horrible thing. If the data has not been replicating for some reason over the past few months and the slave gets promoted with data that’s a few months old, it can be a horrible, horrible thing. I suggest running a tool like Nagios on your stack to monitor EVERYTHING you can think of. A good way to check if your DRBD servers are in sync is to look for the term UpToDate/UpToDate in /proc/drbd.
MySQL Cluster
There are two ways of running your MySQL server in high redundancy. One simple method using tools you’ve already used is to have the MySQL data store running over DRBD and have Heartbeat keeping it in track. This is pretty simple to set up and I’m running it on one of my sites without a problem.
The problem with running MySQL in this sort of setup is scale. Putting your web servers behind a load balancing proxy is a good first step in allowing for you to slot more servers in your solution and starting to scale out. Once the bottleneck moves to your MySQL server, running a single active/passive pair over DRBD won’t scale out, only up (more expensive, faster hardware).
The second time I had to set this up, I chose to run my servers in a MySQL cluster. This means that whenever a transaction is committed on the master, it is sent to the slave to commit as well. The advantage with this is that it allows you to spread out SELECT queries among your slaves instead of running everything on your one server.
Word for the wise
Now we have a highly available network stack in place with highly available system services, we can sleep better knowing that if a system outage were to occur, we have our insurance policy in place knowing that in about 50 seconds, a network issue can converge and services can be automatically moved over to hot standby machines. This does not however give you an excuse to not have a backup strategy in place.
If you’re doing backups as an afterthought, I can recommend setting up an OpenIndiana machine running ZFS on it. Setting it up like I have off site with rotating snapshots. At our work we do nightly backups and for us it’s as simple as doing a database dump, then rsync’ing everything over to this remote ZFS machine to get snapshotted, feeling safe I can access old data from 6 weeks ago (my nightly snapshot period.)
What’s to come?
If you’ve got this far, Thanks for reading and I hope this post pointed you in the right direction to help build highly available services. I think more and more in today’s world people are expecting IT infrastructure to be always up and available. If you don’t have standby servers available, sooner or later, you’re bound to have unhappy customers. I’ve always wanted to build a disaster recovery site, with a highly active database so that in the event of an entire site failing over (think natural disaster, people errors and the like) a site can fail over to another physical disaster recovery (DR) location.